Writing an efficient game representation for chess
2024-02-12
I’ve recently (re-)fell in the good old rabbit hole that got me into computer science in the first place: chess programming.
This is probably my third or fourth rewrite of chameleon-chess, except this time I’m pretty happy with the game representation, which was a huge blocking point for me before. So, as always when I’m happy that something works, I’d like to write about how!
What’s a game representation? Why do we care?
Chess engines (and many board game bots) can be separated into three core components:
- game representation, responsible for encoding game state and actions from one state to another.
- search algorithms to find the best action given a game state.
- evaluation, heuristics to guess the probabilities of winning when we’re in a certain state.
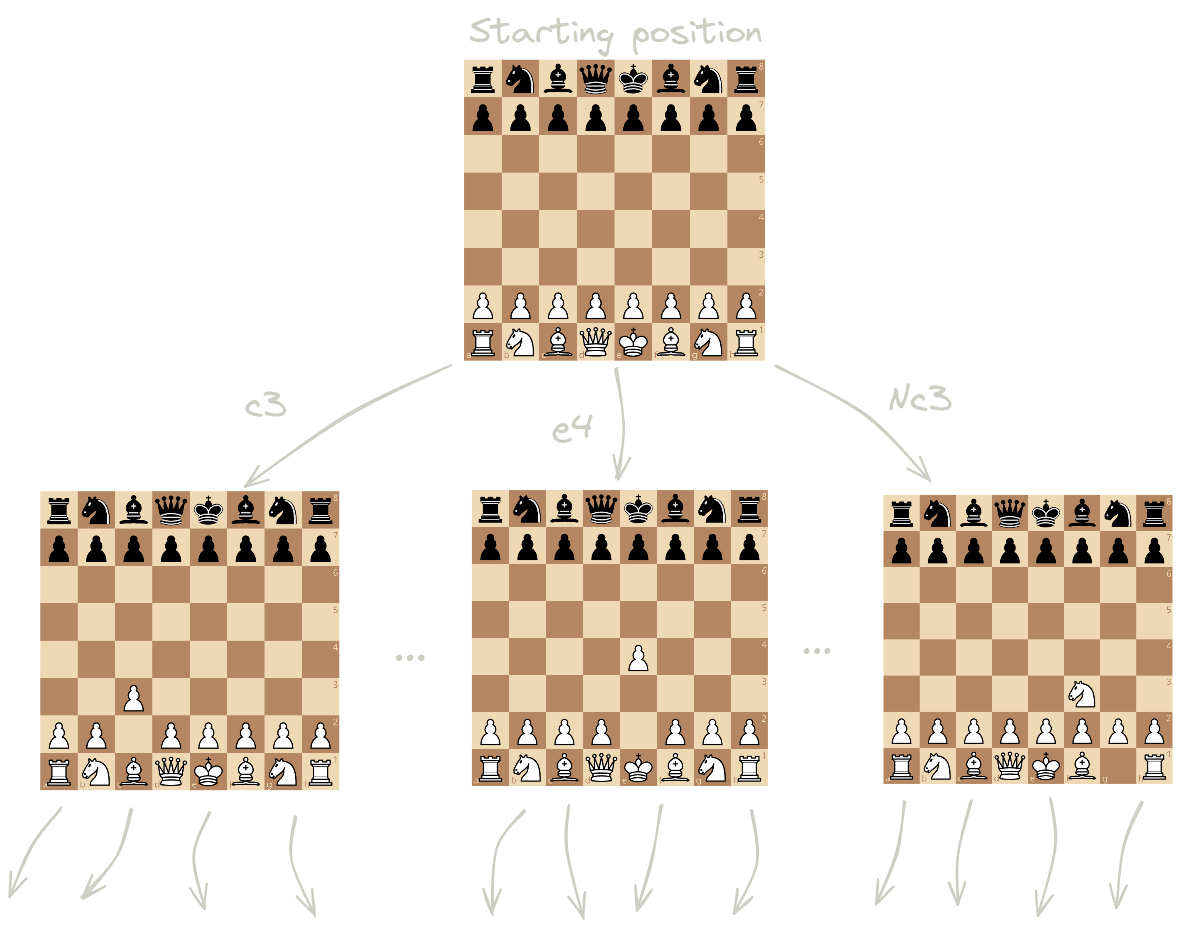
If you’ve got some knowledge about computer science, a game representation can be thought of as a really really big directed graphs with an edge from state A to B is there is an action that can transform A into B when applied.
 { max-height=40em }
{ max-height=40em }
Games are often really, really big, too big to fit into memory, which is why we define the graph implicitly.
Some games like tic-tac-toe are small enough to represent entirely in memory, but since chess has more legal positions than there are atoms in the observable universe, we might want to avoid trying to do that.
Game representation is a bit of a sore spot for me. To put it bluntly, it can break but not make your engine.
A bad game representation leads to really poor performance, yet a good one does not make your engine inherently stronger. This imbalance is caused by the fact that you rely on game representation to traverse game states, so it need to be at least really really efficient. But you also want to avoid traversing the tree too much, so the stronger your engine becomes, the less game representation speed is relevant.
Writing an efficient and correct game representation is still necessary, and there aren’t a ton of detailled tutorials on how to do so. Let’s fix that!
The chess programming wiki offers a lot of information on various techniques used, and in great detail!
It just lacks the “put it all together” part most of the time.
Ok, what do we need?
A good first question indeed: what information do we need to store?
A chess position is represented by:
- the position of pieces on the board.
- which player’s turn it is.
- castling rights.
- en passant target square.
There are also a few more metadata fields needed, like keeping track of repetitions or the fifty-move rule, but they’re not that relevant here.
We also need to know how these informations will be used. Actions in chess are moves. We need to be able to know which moves we can make, and how to modify the position’s data to go back and forth between positions given a move.
These will be our three main functions:
fn make(p: Position, m: Move){.rust} modifies the position as if we played the given move.fn unmake(p: Position, m: Move){.rust} resets the position state to what it was before making a move.fn moves(p: Position) -> [Move]{.rust} creates a list of legal moves for a given position.
We could choose to generate pseudo-legal moves, which follow the rules of chess, but might leave the king in check.
Those moves are invalid, which means that we need to check whether they leave the king in check after making them and undoing the move if it’s the case.
Most of the time, this is slower than embedding more checks into the move generation code, so we’ll generate only legal moves.
Encoding our chess board
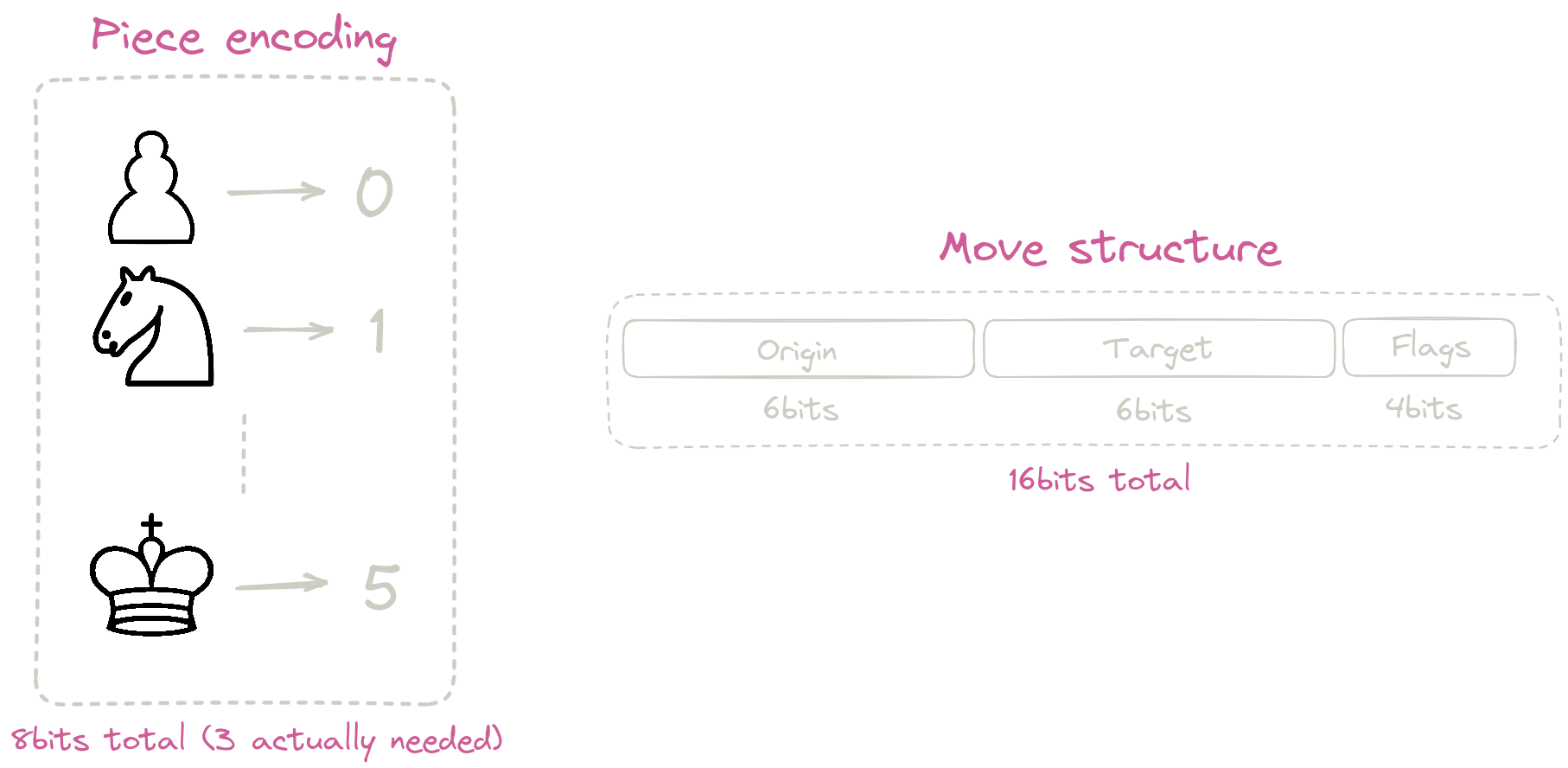
I’ll be keeping this part brief: try to compress your representation. Using the cache efficiently is incredibly important for chess engines.
Applying this, here’s a good and pretty standard way to store moves and piece types:
 { max-height=20em }
{ max-height=20em }
The “flags” part of the move encoding is taken straight from this page
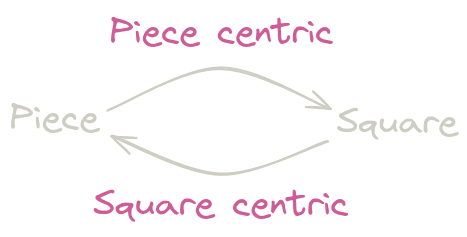
As for the actual board, there are two ways to go about it: piece or square centric. The former keeps information of where pieces are, while the latter keeps information of what is on a given square.
 { max-height=15em }
{ max-height=15em }
- Piece centric representations are faster when iterating over pieces (in move generation for example) because they avoid constantly checking “is there even a piece here?”.
- Square centric representations are faster at answering “which piece is on this square?”, which can be useful when making and unmaking moves.
Therefore, most engines nowadays say… “why not both?”. This wastes a bit of space, and we get redundant information, but it’s way faster to query said information when needed!
My board representation combines an 8x8 array of Option<PieceKind>{.rust} with a piece-centric representation known as bitboards.
Bitboards 101
A bitboard can be thought of as a set of elements that can be indexed, with the bit at index $n$ set to $1$ if the $n^{th}$ element is present and $0$ otherwise.
The cool thing about applying this to chess boards is that we have 64 squares, and can therefore store this set information in a 64 bit integer.
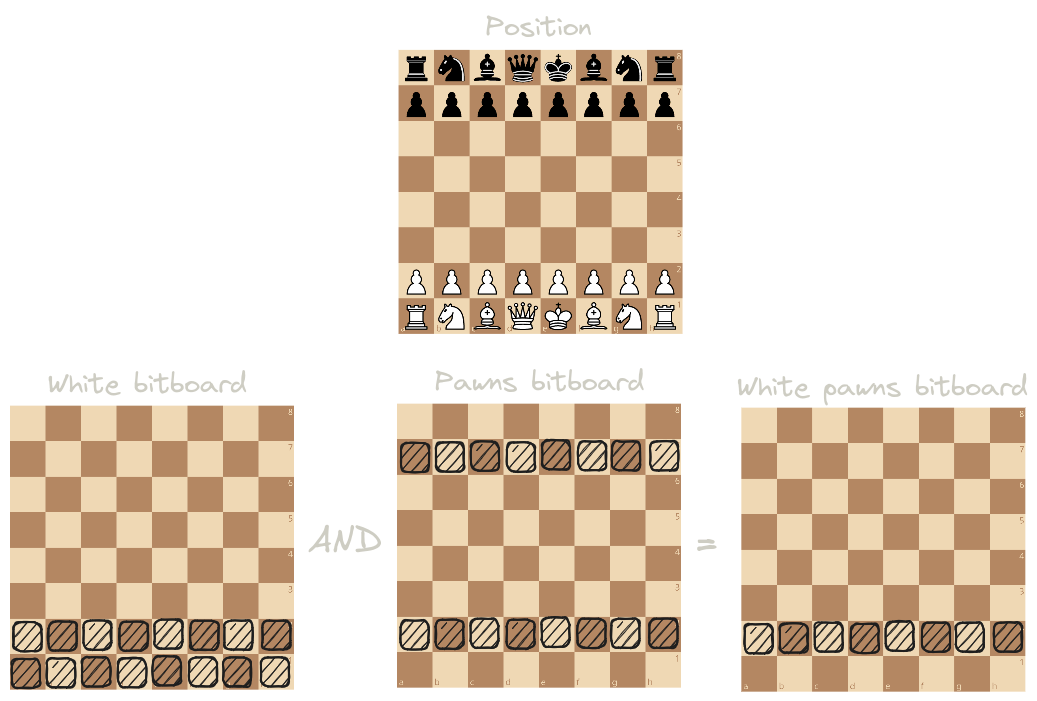
The crux of the idea is to store one bitboard per piece kind and one bitboard per color. We can then do setwise operations in a single instruction.
For example, say we want to get a bitboard of white pawns. Well, this translates to:
let white_pawn_bitboard = pawn_bitboard & white_bitboard
 { max-height=30em }
{ max-height=30em }
This becomes particularily useful when applying shifts, or filtering attackable/movable squares, as we’ll see in a minute.
An important idea of bitboards is serializing. When we get a bitboard of target squares, we cannot transform it into a list of moves directly. We first need to extract the information of which squares are set.
The main way to do it is to find the lowest set bit of the bitboard, then resetting said bit. Keep going until the bitboard is empty and boom, a list of indices of set bits! Yay!
Here’s what this would look like in crude pseudo-code:
fn serialize(bitboard: Bitboard) -> Vec<Square> {
let mut indices = vec![];
while !bitboard.is_empty() {
let square = bitboard.pop_lowest_square();
bitboard.reset_lowest_square();
indices.push(square);
}
indices
}
In reality, a better way to implement this is as an iterator, which would look like this in Rust:
impl Iterator for Bitboard {
type Item = Square;
fn next(&mut self) -> Option<Square> {
if self.is_empty() {
None // If the board is empty, we stop
} else {
let square = bitboard.trailing_zeros(); // Same as finding the lowest set bit
bitboard &= bitboard - 1; // Efficiently reset the lowest set bit
Some(square)
}
}
}
We can now iterate over set square on our bitboard, which is useful for applying all kinds of transformations!
Generating moves
Now we move on to the interesting part: how can we use that to generate moves? I’ll first present general techniques without caring about legality. We’ll handle that afterwards!
Pawns
Pawns are really benefitting from the bitboard representation. We start by filtering pawns which are about to promote, separating them from the rest:
let pawns = pawn_bitboard & side_to_move_bitboard;
let promoting_pawns = pawns & promoting_rank;
let pawns = pawns ^ promoting_pawns;
We can than generate pawn moves by shifting the entire bitboard in different directions.
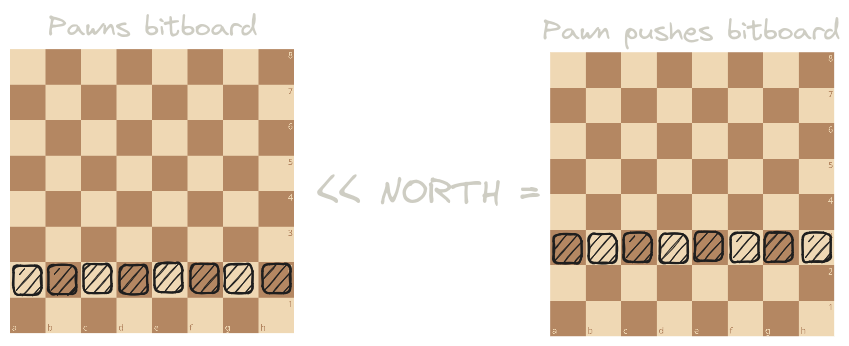 { max-height=20em }
{ max-height=20em }
However, we’re not done here: what if there are already pieces on the squares we want to get to? Pawns can’t capture by moving forward!
Well, we can mask this pawn_pushes_bitboard by an empty bitboard that contains set bits wherever there are no pieces. This bitboard can be obtained by negating the union of our two color bitboards, pretty neat!
 { max-height=20em }
{ max-height=20em }
I’m not going to detail everything here, but the same ideas can be applied for all pawn movements. You generate a set of potential target squares, then mask it by squares that can actually be moved to (empty ones for pushes, enemy pieces for captures, en passant target for en passant captures, etc).
Knights and kings
Knights and kings are different from pawns: there are a looot of deltas that can be applied, and most of the time only two knights and one king. We don’t benefit much from parallelization here.
Instead, we can calculate a lookup table of potential moves for each origin square! We could then access the moves for a knight on d5 this way:
let knight_moves = KNIGHT_LOOKUP[Square::D5];
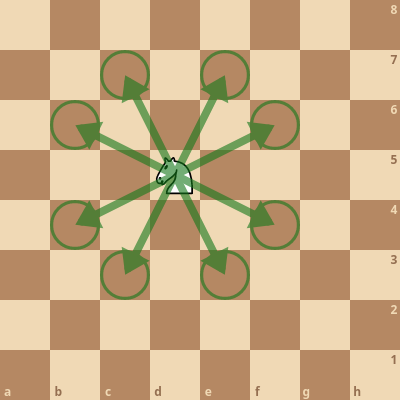 { max-height=20em }
{ max-height=20em }
There’s not much going on for knights and kings (for now) appart from that, they’re pretty simple!
Sliding pieces
Uh oh…
Sliding pieces (bishops, rooks and queens) are a bit more tricky. The main difficulty is the fact that their moves can be thought of as rays that can be blocked by other pieces! We can’t simply create a lookup table associating an attack bitboard from each square like knights and kings, since we also depend on the state of the board.
There are two (main) ways to go about things:
- calculating the attacks using fill algorithms on bitboards (Dumb7Fill, Kogge-Stone or Fill by subtraction are good examples).
- creating lookup tables indexed by square and blockers.
We’ll be focusing on the latter since it is often faster on modern CPUs with big caches. More precisely, we’ll be looking at magic bitboard.
There are other ways to create lookup tables, which I’ll mention briefly:
- rotated bitboards cover line attacks only, and require additionnal bitboards updated incrementally to work efficiently.
- kindergarten bitboard require some more calculation. They are a good middle ground between pure lookup and pure calculation!
The main advantage of magic bitboards is that they cover rook and bishop attacks (two lines) at once rather than a single line each time.
What we’re trying to find is a perfect hash function from blockers to attacks for each square. If this seems like a complex endeavour, you’d be right! Thankfully, smarter folks have already thought about it for us.
First of all, we don’t want to perfectly hash all possible blocker setups. Taking a bishop on e4, it doesn’t matter to us wether a piece is on d2: we wouldn’t cross it anyway.
What we want is, once again, to mask relevant blockers and use this as a key. Already, we’ve simplified our search quite a bit!
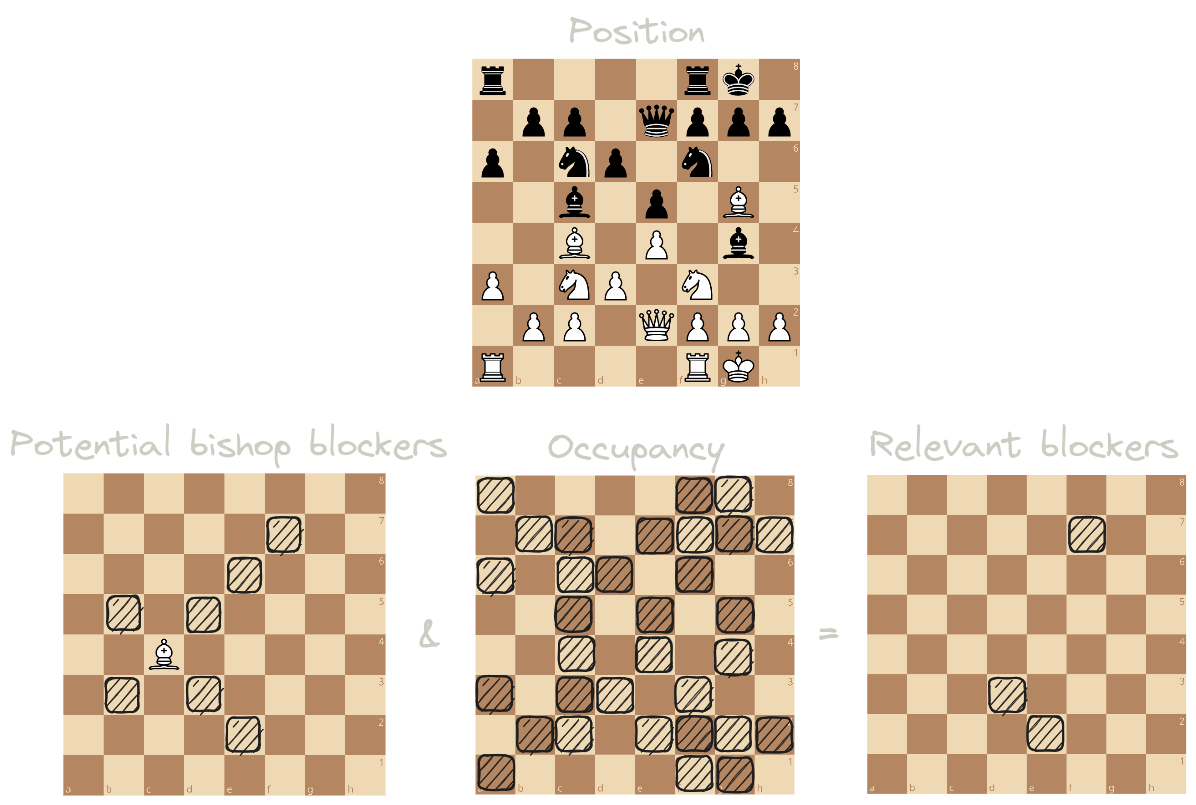 { height=40em }
{ height=40em }
Now, we’ve got a little problem… how do we transform our relevant blockers into a unique key?
Well, folks, I present to you the solution to any complex problem: brute-force!
Yup, you’ve heard that right, what we’re going to find is a magic number (thus the name) that, when multiplied with our bitboard and then shifted by a number of bits $n$ (often the number of relevant blockers) perfectly maps blockers to the correct set of attacked square.
There is a great article by Analog Hors on the process of computing and using said magic numbers, so I won’t delve into it too deeply. Just remember that we have a function that, given an origin square and a set of blockers, returns the squares attacked by a bishop/rook on said origin square.
There are a lot of improvements for magic bitboards. Some are dependant on specific hardware instructions, others are implemented using more advanced hashing functions.
There are also improvements to be made on magic numbers themselves. There is an ongoing effort to find magic numbers requiring less bits, which reduces the space required to store our informations.
As mentionned before, small gains get more and more negligeable past a certain point. Magic bitboards are more than sufficient for now, and the small improvements granted by more advanced implementations tend to get negligeable within an engine, so I won’t talk about them here.
Still, it’s a depply interesting
rabbit holetopic to dive into if you’ve got time to dedicate to it! Current magic numbers are a bit wasteful, so maybe you’ll be the one to find better ones, who knows?
So how do we use this? Well, similar to knights and kings, we iterate over all sliding pieces and lookup what moves they can make!
A quick heads up: it is faster to separate between diagonal sliders (bishops and queens) and orthogonal sliders (rooks and queens). This way, our lookups are easier to encode.
// Iterate over our bishops and queens
for origin in diagonal_sliders {
// Lookup our moves from the magic table
let moves = diagonal_moves(origin, !empty);
// Then generate captures and quiet moves
for target in moves & ennemy_pieces {
// Some move encoding stuff for captures
}
for target in moves & empty {
// Some move encoding for quiet moves
}
}
“That was an illegal left by the way”
Okay, okay, let’s make sure our moves are legal now!
First, let’s see… Which of our generated moves could be illegal? Well, there are a few:
- moves of a piece that would leave the king in check. Such pieces are called absolutely pinned and cannot move except along the ray that pins them to the king.
- en passant captures can, in specific cases, leave the king in check by making two pawns disappear on the same rank.
- moves other than the king’s if it is checked by two or more pieces.
- if the king is checked by a single piece, moves that do not capture the checking piece or block the attack ray.
- in general, king moves to attacked squares.
- castling over attacked squares.
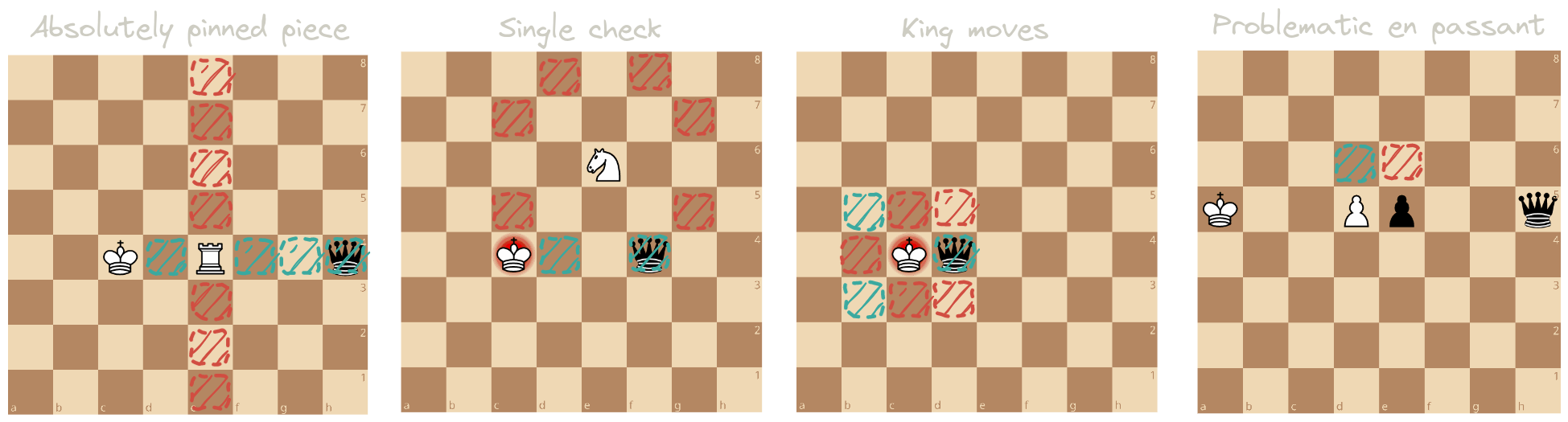 { height=20em }
{ height=20em }
Phew, okay, how do we deal with that?
Pins, checks and attacks
Three informations are clearly of importance here:
- whether the king is in check, and if so, does more than one piece attack it?
- which pieces are pinned, and where can they move?
- which squares are attacked?
This all depends on moves that the ennemy pieces can make! We don’t want to generate every move for every ennemy piece tho, that would just double our workload and is unnecessary.
What we’ll do instead is compute three bitboards:
- attacked squares.
- checking piece(s).
- pieces of the moving side which are not pinned.
This is done by generating attack targets (not actual moves, the distinction is important) for all ennemy pieces.
Some game representations separate the routine of detecting pins, generating moves for pinned pieces and generating attacked squares.
Most of the time, it is more efficient to do all three in one pass, since they all reuse information from one another. It is less readable and more error prone, but worth it in the end!
Pawns, knights and kings cannot create pins. This makes it easier to deal with them: just generate their attack targets and add them to the bitboard of attacked squares.
attacked_squares |= KING_LOOKUP[ennemy_king];
for knight in ennemy_knights {
attacked_squares |= KNIGHT_LOOKUP[knight];
}
// Same for pawns
If at this point the attack bitboard intersects with our king bitboard, we’re in check! We generate attacks from our king, and intersect them with ennemy pawns/knights, then add the result to the checking pieces’ bitboard.
if attacked_squares & allied_king {
checkers |= KNIGHT_LOOKUP[allied_king] & ennemy_knights;
// Same for pawns
}
I’ve left out the ennemy king in that last part. The reason is that it cannot ever check our own king, otherwise we’d already be in an illegal position.
Now we get to the fun part: sliders.
First, the attack bitboard. One may think that simply looking up magic bitboards as we usually do would work, but this leads to a sneaky bug: our king could slide away from a check.
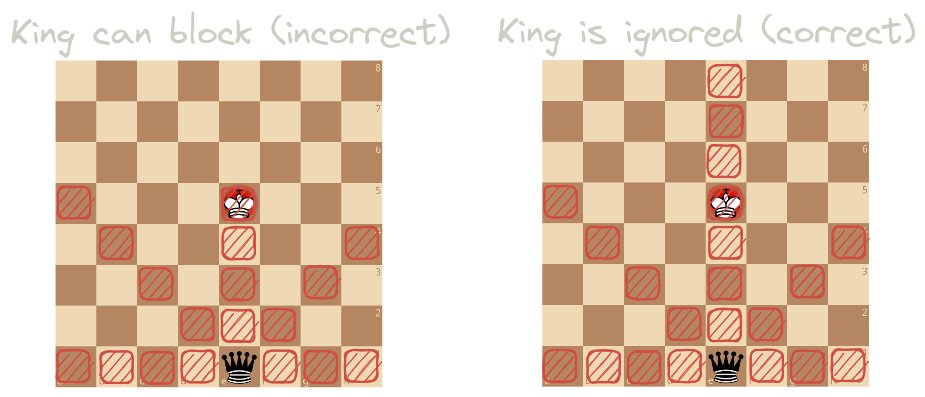 { height=20em }
{ height=20em }
You might notice that some squares here are not actually attacked. So is our attack bitboard wrong?
Well, if we’re asking for a set of actually attacked squares, yes, it is wrong. But we’re only interested in squares our king cannot move to or squares that we cannot castle through. Here, both are valid.
Other than that, generating the attack map has no weird intricacies, so we’re done here:
// Example for diagonal sliders
for origin in diagonal_sliders {
attacked_squares |= diagonal_moves(origin, blockers & !king);
// (rest of the code for handling pins and checks...)
}
But, as we said above, we want to generate moves for pinned pieces and detect checks while we have this attack information as well!
Checks are easy to detect: we just need to assert whether the attack rays intersect with our king. If it does, bing bong, you’re in check! The piece is added to the bitboard of checkers as usual.
On top of that, we generate a ray along which our pieces can move to block the check. The way I do it is by generating corresponding slider moves originating from our king and bypassing our pieces. The intersection of those attacks and the attacking piece moves will give us our attack ray!
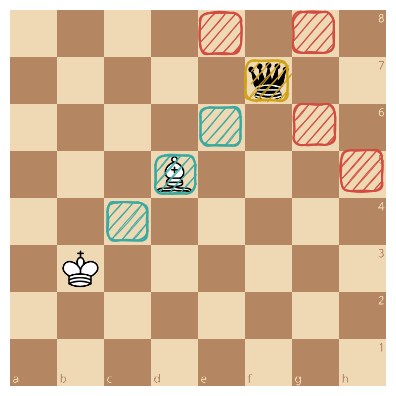 { height=20em }
{ height=20em }
This ray from our king can also be used to detect pins. If the king attack intersects with a corresponding ennemy slider, we simply need to count how many of our pieces intersect with the pin ray.
The additionnal lookups for crafting the actual ray must be guarded by a conditional! Otherwise, they can be pretty damn costly.
If there is only one, it is pinned. At this point, we can generate moves only if they target the pin ray.
We then must carefully remove the pinned piece from normal move generation. This is done by adding it to the pinned pieces bitboard, which we’ll use as a mask over our pieces in the rest of the move generation.
Adapting the rest of move generation
Let’s sum up the modifications we made. We have access to:
- a bitboard of allied pieces which are not pinned.
- a bitboard of checking pieces.
- a set of squares that pieces can move to.
- a bitboard of attacked squares.
First, we’ll differentiate between our 3 cases: the king can be in single check, double check, or not attacked. We can find this information by counting the number of checking pieces.
- if there are no checkers, we change the set of squares that pieces can move to to be empty squares, and change the set of squares we can capture to squares where there are ennemy pieces. We also generate castling moves if applicable.
- if there is at least one checker, we need to clear up potential pinned piece moves generated previously since they are not legal anymore.
- past two checking pieces, we skip generating moves for general pieces and only generate king moves.
let checkers_count = checkers.count_ones();
if checkers_count == 0 {
// Change our quiet moves and captures targets.
movable = empty_squares;
capturable = ennemy_pieces;
// Generate castling moves.
generate_castling_moves();
} else {
// Clear up previously generated moves for pinned pieces.
moves.clear()
}
if checkers_count < 2 {
// Generate moves for other pieces
}
// Generate king moves
let king_moves = KING_LOOKUP[king_square] & !attacked_squares;
// ...
The only thing that changes for the king is that we mask its potential moves not only with the usual empty squares/ennemy pieces, but also by !attacked_squares{.rust}
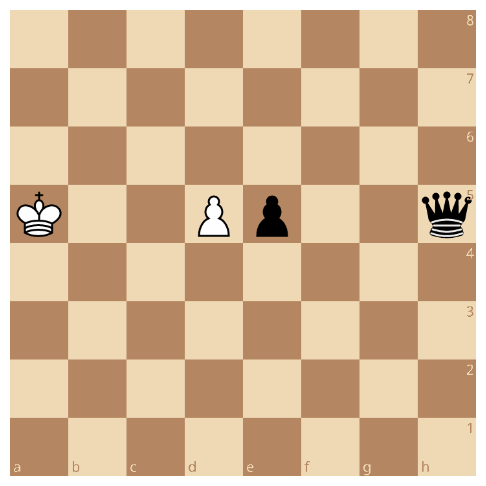
Problem: en passant discovered check
 { height=20em }
{ height=20em }
Well, it’s time to deal with it now! We’ll also take time to actually deal with en passant captures after delaying that for most of this post.
En passant captures are hell and I despise them from the bottom of my heart. Chess is generally pretty smooth when it comes to its rules, and then they throw this random, once in a blue moon move that is hard to deal with when programming!
Our main problem is the fact that capturing en passant can discover a check on the king even tho the pawn isn’t pinned!
The advantage of en passant tho is that it is extremely rare, so generating en passant moves a bit slowly is not that bad and we can focus on correctness.
What we need to do is identify the captured square, the capturer, and check if an orthogonal ray from our king following the rank the en passant capture happens on, removing both the captured and capturer from the blockers bitboard, reaches a queen or rook.
At first, I had an additionnal check for discovered checks from bishops, in such positions for example:
{ height=20em }
In reality, such positions cannot happen after a series of legal moves. The reason is that there are only two ways we can get into such a position:
- either the pawn just moved, and therefore the bishop was already checking our king, which cannot be legal.
- or the bishop just moved, and therefore the pawn cannot be captured en passant anymore.
General performance tips
Sadly, this last “implementation” section will be reaaaally specific to Rust, since that’s the language I’m using to implement this move generator. Still, you might find ways to apply those tips in other languages!
Generic functions
Move generation is dependant on which side is currently moving. Things like the directions pawns move towards, ennemy pieces, etc.
You could do all of that with a bunch of if{.rust} statements and pray that the branch prediction gods are on your side (they often are), but a little nudge in the right direction certainly helps!
One way to do so is to pack two side-specific functions (one for white, one for black) and choose between them at the start of move generation. Writing two functions is just a way to create more bugs duplicate logic, so we instead use Rust’s const generics.
fn moves(&self) -> Vec<Move> {
fn moves_generic<const BLACK_TO_MOVE: bool>(position: &Position) -> Vec<Move> {
// Logic goes here
}
if self.black_to_move {
moves_generic::<true>(self)
} else {
moves_generic::<false>(self)
}
}
You can then use the BLACK_TO_MOVE{.rust} constant within the inner function, and Rust will actually generate the two specific functions during compilation!
Trust our benevolent branch predictor
Going the exact opposite of what has been said above: trust branch prediction!
If you have work that is tedious and unlikely to be required, put it in a branch. Generic functions can only go so far, and there are some things that cannot be known statically.
For example, querying the magic bitboards a second time to generate rays for pinned pieces is unlikely to be necessary. Putting it under a conditional saves time!
Use the stack, dammit!
Storing our generated moves in a Vec<Move>{.rust} is sloooooooooow… Thankfully, Rust provides some libraries crates for stack vectors (which are just fixed size arrays where not every element is initialized, adding some push{.rust} and other nice APIs).
The example I’m using is called arrayvec, allowing me to avoid recoding one myself. Yay, lazyness!
Iterators! Trust me, they’re optimized
When serializing moves, you might want to use iterators a lot. More notably the extend{.rust} function, which lets you add the elements of an iterator in a collection all at once.
The advantage over a for loop is that if you know the size of your iterator (as we do here, since we can just call count_ones on our bitboards of target squares), the collection will grow only once, and then everything will be pushed without incrementing the lenght each time.
This information is given to the compiler by implementing the
ExactSizeIterator{.rust} trait.
Basically, it allows you to do everything in a batch! This saves a bunch of precious operations during move generation.
Generally speaking, Rust’s iterators are really efficient, so it’s always a good idea to rewrite for loops using them to see if it improves your performance.
The “checking” part is thoroughly important, and I cannot emphesize this enough! Sometimes, for loops are faster, you can’t know unless you try and benchmark the change.
For example,
chain{.rust} orflat_map{.rust} make performance worse, because they never implement theExactSizeIterator{.rust} trait that our optimization relies on!
So, is this even correct?
Welp, I’m a computer scientist at heart so my answer will be: I don’t know… but I can still be highly confident that it is correct!
The main method of testing for game representations is perft. The idea is to walk the game tree, counting how many nodes are accessible up to a certain depth. Results for chess have been thoroughly discussed and validated by many many people, so we can be pretty confident that they are correct.
Thus, we simply have to check that our game representation outputs the same number of reachable positions! Easy!
The reason I’m saying that I’m not certain that my game representation is correct is because those results aren’t in any way proven.
One way to be absolutely certain, 100%, that those numbers are correct would be to create a formally verified game representation using tools like Coq or Agda. This could be a fun project someday, but it waaaaay out of the scope of this already too long post!
Aaaand… guess what? It seems we’re good to go!
~/D/chameleon-chess > target/release/perft -bip 8
r n b q k b n r
p p p p p p p p
. . . . . . . . side to move: white
. . . . . . . . reversible moves: 0
. . . . . . . . en passant: -
. . . . . . . . castling rights: KQkq
P P P P P P P P hash: 0x1f5ca3327330cf5e
R N B Q K B N R
depth 1: 20 nodes
depth 2: 400 nodes
depth 3: 8902 nodes
depth 4: 197281 nodes
depth 5: 4865609 nodes
depth 6: 119060324 nodes
depth 7: 3195901860 nodes
depth 8: 84998978956 nodes
I’ve tested the code on other positions as well, with all positions correct up to decent depths!
And how fast is it? Three fasts? FOUR FASTS???
Perft is also a good way to compare the speed of game representations, since it makes use of every function we’ve defined so far!
We’ll make a little contest, comparing my game representation to QPerft. The former uses a square-centric board representation and is deemed the baseline against which most engines compare their game representation. In the [mailbox trials], it was deemed comparable in speed to Stockfish’s bitboard representation.
I planned on including Stockfish itself to this comparison at first. The thing is, recent Stockfish implementations include an NNUE, which slows it down dramatically.
Simply put, it wouldn’t have been fair to compare two game representations made specifically for the perft test against one that embeds a full neural network in its game representation!
For reference, the benchmarking setup involved running each of the usual perft positions on each competing program. This is done using hyperfine. The code ran on an AMD Ryzen 5 5500U, in single core iterative perft with bulk-counting on horizon nodes.
Here are the fabled results:
| start (7) | kiwipete (6) | endgame (8) | mirrored (6) | talkchess (5) | alternative (6) | mean (deviation) | |
|---|---|---|---|---|---|---|---|
| chameleon-perft | 12.662s (252Mnps) | 24.432s (329Mnps) | 13.212s (228Mnps) | 2.103s (336Mnps) | 0.274s (328Mnps) | 20.773s (333Mnps) | 301Mnps (~47.9) |
| qperft | 12.612s (253Mnps) | 33.286s (241Mnps) | 23.310s (129Mnps) | 4.354s (162Mnps) | 0.502s (179Mnps) | 18.519s (374Mnps) | 223Mnps (~87.8) |
Damn, that’s pretty efficient! We beat or equalize with QPerft on almost every position!!! It’s safe to say that our game representation is good enough at this point.
Note that this happens on my specific CPU, results may vary dependending on architecture, instruction set, etc.
This is especially true for bitboard representations, which rely on bit tricks and lower level instructions. For example, if your CPU has a slow “trailing ones” instruction (or none at all), bitboard serialization takes a serious hit!
What’s next?
We’ve got ourselves a really nice game representation, so there are only a few things left to do:
- use it in an actual, complete chess engine (notably embedding it into
chameleon, a general game playing framework that I’m developping on the side). - procrastinate by implementing more complex magic bitboards schemes, since shared attacks look really juicy.
- work on actual school projects that are mandatory and on which my future depends (least likely).
Anyway, as a thanks for reading this loooooong post, here’s the repository where all of the actual code lives!
See ya!